What is an LLM? How large language models work



Large language models (LLMs) power the AI tools millions of people use every day, from writing assistants and search engines to customer support bots and coding assistants. Yet for many people, what's happening under the hood remains unclear.
What is a large language model?
An LLM is a type of AI trained to process human language and generate responses that sound conversational and context-aware. It uses machine learning (ML) and deep learning techniques to analyze large volumes of text data, identify language patterns, and predict which words should come next in a sentence.
The term "large" in LLMs refers to both the size of the training dataset and the number of parameters the model uses. Parameters are internal values that the model adjusts during training to improve its accuracy in predicting and generating text. Modern LLMs often have billions of these parameters.
LLMs are a major part of generative AI. While generative AI encompasses systems that create text, images, audio, video, or code, LLMs focus specifically on language-based tasks.
Why large language models matter
LLMs have changed how people interact with software and information online. Instead of searching through pages of links or manually completing repetitive tasks, users can now ask questions in plain language and receive direct answers or generated content in seconds.
Additionally, tasks that once required specialist skills or significant time investment, such as drafting content, analyzing data, writing code, and processing customer inquiries, can now be handled, at least in part, by an LLM.
Examples of popular LLMs
Several LLMs are now widely used in consumer and business settings, each with its own training approach, strengths, and intended use cases. Some popular ones include:
- GPT (OpenAI): An LLM developed by OpenAI and used in ChatGPT for tasks like writing, coding, research, and conversation.
- Gemini (Google): Integrated across Google's products, including Search and Workspace.
- Claude (Anthropic): Designed with a focus on safety and reliability across a range of tasks.
- Qwen (Alibaba): An open-weight model family with versions designed for local deployment and flexible self-hosting.
- DeepSeek R1: An open-weight model that drew attention for its performance relative to its cost.
How do large language models work?
LLMs work by analyzing patterns in language and using them to predict what content should come next based on a user’s prompt. Instead of memorizing exact answers, an LLM learns relationships between words, phrases, topics, and sentence structures during training.
How LLMs learn from massive datasets
Before an LLM can generate anything, it needs to be trained. That process relies on enormous datasets made up of text gathered from books, websites, academic papers, code repositories, news articles, and other sources. Frontier LLMs are often trained on datasets measured in hundreds of billions to trillions of tokens.
During training, the model is exposed to this text repeatedly and learns to recognize patterns: which words tend to follow others, how sentence structure changes with context, what different topics look like in language, and how meaning shifts depending on phrasing.
These relationships are encoded in the model's parameters. Generally, the more parameters a model has, the more nuanced the patterns it can learn, though performance also depends on factors like training data and architecture.
As part of the training, the model repeatedly tries to predict missing or next words in sentences. If its prediction is wrong, the system adjusts its internal parameters to improve future predictions. Through these adjustments, the model becomes better at recognizing language patterns, grammar, context, and common relationships between concepts. Many modern LLMs then undergo an additional reinforcement phase, where human reviewers or more advanced "teacher" models evaluate and rank responses. This helps steer the model toward outputs that are more useful, accurate, and/or aligned with human expectations.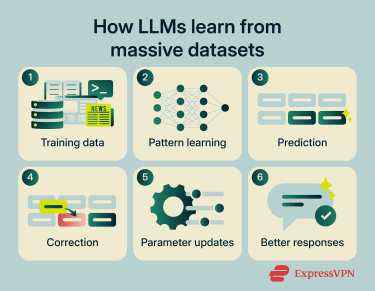
Neural networks, transformers, and text generation
LLMs are built on neural networks, which are computational systems loosely modeled on how the brain processes information through connected layers of nodes.
Many modern LLMs use a specific type of neural network called a transformer. Introduced in the landmark 2017 research paper Attention Is All You Need, the transformer architecture changed the field by making attention mechanisms central to language processing. Attention allows a model to weigh the relevance of different words in relation to one another, regardless of how far apart they appear in a sentence. This helps the model understand context and relationships more effectively than many earlier approaches, enabling major advances in language understanding and generation.
LLMs generate responses through a process called inference. When you enter a prompt into an AI chatbot or assistant, here's what happens:
- Tokenization: Your text is broken into smaller units called tokens, which are roughly equivalent to words or parts of words.
- Encoding: Each token is converted into a numerical representation that the model can work with.
- Attention: The transformer weighs the relationships between all tokens in your input simultaneously, building a rich picture of context and meaning. This process happens within the model’s context window, which is the amount of text the AI can keep “in mind” at once, including your prompt and earlier parts of the conversation.
- Prediction: Working through its layers, the model generates the next most probable token, then the next, and so on, until the response is complete.
- Decoding: Those tokens are converted back into readable text and returned to you.
This process happens in milliseconds and repeats token-by-token until the output is complete. The model isn't retrieving a stored answer; it's constructing one, word by word, based on learned probability.
How are LLMs trained?
Modern LLM training generally happens in multiple stages, including pretraining, instruction tuning, fine-tuning, and reinforcement learning.
Pretraining large language models
Pretraining is the first major stage of LLM training. During this phase, the model learns general language patterns by analyzing extremely large text datasets, often hundreds of billions to trillions of tokens. For example, if the model sees the phrase “The capital of France is,” it learns that “Paris” is a highly likely prediction based on patterns it’s seen during training.
This is called self-supervised learning. The model doesn't need labeled data or human-annotated examples; it learns purely from patterns in the text itself.
By working through this process billions of times, the model becomes better at understanding grammar and sentence structure, word relationships and context, general world knowledge, coding syntax, and technical language.
Fine-tuning for specific tasks
After general training, developers may fine-tune an LLM for specialized tasks or industries. Fine-tuning involves training the model further on smaller, more targeted datasets related to a particular domain or function. This helps improve performance for specific use cases.
For example, organizations may fine-tune models for:
- Customer support systems
- Medical research tools
- Legal document analysis
- Coding assistants
- Financial analysis platforms
- Internal business knowledge bases
A coding-focused model might receive additional programming datasets, while a healthcare-focused system may train on medical terminology and research literature.
Instruction tuning
Instruction tuning helps an LLM learn how to respond to prompts more effectively and follow user instructions conversationally. During this stage, developers train the model on examples of prompts paired with high-quality responses. These examples teach the model how users typically ask questions and what kinds of answers are expected.
Without instruction tuning, a pretrained model might generate text that is technically related to the prompt but not especially useful or aligned with user intent. Instruction tuning closes that gap, making models considerably more practical for real-world use.
Reinforcement learning from human feedback
The final major training stage is reinforcement learning from human feedback (RLHF). This is where human judgment is used to steer the model toward outputs that aren’t just coherent and instruction-following but also accurate, helpful, and appropriate.
In practice, human reviewers evaluate pairs of model responses and indicate which is better. Those preferences are used to train a separate reward model. This is a system that learns to score outputs based on what humans tend to prefer. The LLM is then fine-tuned further using reinforcement learning to maximize that reward signal.
RLHF is one of the main reasons modern LLMs feel more conversational and better calibrated than earlier AI systems. It's also part of how developers try to reduce harmful or misleading outputs. They explicitly reward responses that are safer and more helpful and penalize those that aren't.
What can LLMs do?
LLMs are general-purpose tools, which means they can be applied across a wide range of tasks. Below are some of the most common ways LLMs are used today:
Content creation and writing
LLMs can draft, edit, summarize, and rewrite text across formats, including articles, emails, reports, blog posts, social media posts, product descriptions, marketing copy, and more. They can adjust tone and style based on instructions, condense long documents into summaries, and generate first drafts that humans can then refine.
Coding and software development
LLMs trained on large code repositories can write, explain, debug, and review code across multiple programming languages. Developers use them to generate boilerplate code, suggest fixes for errors, translate code between languages, and document existing functions.
Customer support and chatbots
Businesses use LLM-powered customer support systems and conversational AI assistants to automate common support tasks such as answering FAQs, assisting with troubleshooting, providing account information, routing users to support teams, and summarizing conversations.
Translation and language processing
LLMs can process and generate text across multiple languages, making them useful for translation and communication tasks. Unlike earlier translation tools that operated largely word-by-word, LLMs understand context across sentences and paragraphs, producing translations that are more natural and less prone to misreadings.
Research and data analysis
LLMs help researchers navigate large bodies of literature by summarizing papers, identifying relevant sources, explaining complex topics, and extracting key findings from documents. In business settings, they're used to analyze unstructured data such as customer feedback, interview transcripts, and internal reports, finding patterns far quicker than manual review would allow.
Sentiment analysis
Sentiment analysis involves identifying whether a piece of text expresses a positive, negative, or neutral view, and LLMs have shown strong performance in this. Unlike earlier sentiment tools that relied on keyword lists or simple classifiers, LLMs can pick up on irony, context, and nuance in ways older tools missed.
Businesses use LLM-powered sentiment analysis to monitor customer reviews, track brand perception across social media, and flag issues in support ticket queues before they escalate. In many cases, the model isn't generating text at all. Instead, it's used to create a rich numerical representation of the content, often called an embedding, which can then be analyzed to classify sentiment or identify patterns in large volumes of text.
What are the benefits of LLMs?
LLMs offer several advantages for both individuals and businesses. Here’s a look at some of the main advantages:
- Faster content generation: One of the most immediate benefits of LLMs is speed. Tasks that once took hours, such as drafting a report, summarizing a long document, translating content into another language, or generating product descriptions at volume, can now be completed in minutes. This frees up time for higher-value, strategic tasks.
- Improved automation: LLMs enable organizations to automate workflows that previously required manual effort. For example, customer emails can be triaged automatically, and internal knowledge bases can be queried in plain language.
- Better user experiences: LLMs make software interfaces more conversational and accessible. Natural language interfaces where someone types a question and gets a useful, conversational answer are now common across search engines, customer support tools, productivity apps, and more. This helps lower the barrier to using complex software and makes digital tools easier for non-technical users to navigate.
- Scalable AI solutions for businesses: LLMs are scalable; a single model, once deployed, can handle thousands of simultaneous interactions without additional headcount. This allows organizations to handle workload peaks and grow sustainably without proportional increases in operational costs. For example, a company that couldn't previously afford a 24/7 multilingual support operation can now deploy an LLM-powered system that handles it.

What are the limitations of LLMs?
While LLMs can generate convincing responses and automate many tasks, they don’t truly understand information the way humans do. This introduces various risks and limitations, including:
- Accuracy and hallucination issues: LLMs generate responses based on patterns in training data rather than retrieving facts from a verified database. This can lead to hallucinations, where the model produces confident but incorrect information, such as fake citations, outdated facts, inaccurate code, or misleading answers.
- Bias and ethical concerns: Because LLMs learn from human-generated content, they can absorb and reproduce social, cultural, and political biases, including discriminatory patterns in high-stakes decisions like hiring.
- Data privacy and security risks: Some AI platforms raise privacy concerns because they might store or use sensitive information shared in conversations, and LLMs can be exploited through prompt injection attacks, phishing campaigns, and social engineering at scale. Some privacy-focused AI platforms like ExpressAI are designed to reduce these risks through a zero-access architecture, where conversations are encrypted and processed inside secure enclaves so that neither the provider nor model operators can view or store user inputs.
- High training and computing costs: Training frontier models requires massive hardware resources and can cost tens to hundreds of millions of dollars, creating high barriers for smaller organizations and significant energy consumption.
Real-world applications of large language models
LLMs are already used across many industries and consumer technologies.
LLMs in healthcare
Some common LLM use cases in healthcare include summarizing patient notes, assisting with medical documentation, analyzing research papers, supporting clinical decision-making, powering healthcare chatbots, and translating medical information into simpler language.
LLMs in education
In education, the most significant application is personalized tutoring through:
- Intelligent tutoring systems: LLM-powered tutors engage students in back-and-forth dialogue, adjust explanations based on prior responses, and provide immediate feedback.
- Personalized content: LLMs generate explanations, exercises, and examples tailored to a student's level.
- Accessibility: Students in remote areas or without access to tutors can get responsive, on-demand academic support.
LLMs in marketing
Marketing teams were among the earliest adopters of LLMs. Some common uses of LLMs in marketing include generating content at scale, personalizing customer messaging, offers, and recommendations, sentiment analysis, and marketing research.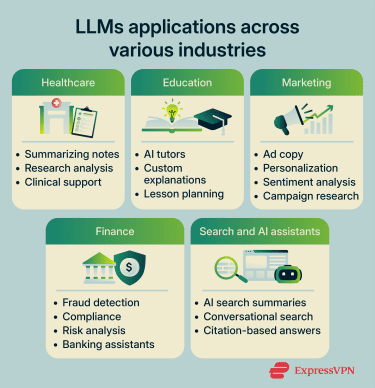
LLMs in finance
Financial services have quickly adopted LLMs to assist with creating contracts, filings, compliance documents, research reports, and customer communications. LLMs are also widely used in financial customer support.
LLMs in search engines and AI assistants
The traditional search model, where people type a query and get a list of links, is increasingly being supplemented by LLM-powered responses that synthesize information directly. For instance, search engines like Google and Bing have introduced AI overviews that synthesize search results into AI-generated summaries. Dedicated AI search engines like Perplexity have also grown rapidly, offering citation-backed answers rather than ranked lists of links.
The future of large language models
LLMs are evolving quickly, and researchers continue to push AI systems beyond basic text generation. Future models are expected to become even more capable, personalized, and integrated into everyday software and workflows.
Here are some trends that are expected to shape the future of LLMs.
Multimodal AI and advanced reasoning
Early LLMs worked exclusively with text. Today's leading models accept and generate combinations of text, images, audio, and video, a capability known as multimodal AI. This shift expands the kinds of tasks and problems these systems can tackle.
A multimodal model can examine a medical scan and generate a written summary or help a developer debug code by interpreting a screenshot of an error. As models gain the ability to process video and audio in real time, the range of applications will expand further.
Alongside multimodal capability, reasoning is advancing rapidly. Newer LLM architectures use extended reasoning techniques, which involve working through problems step by step before producing an answer. This can meaningfully improve performance on complex tasks like mathematics, logic, and multi-step analysis.
The combination of multimodality and better reasoning is enabling agentic AI systems that don't just answer questions but plan and execute multi-step tasks autonomously, use tools, browse the web, and coordinate across systems on a user's behalf.
Open-weight vs. closed-source LLMs
Closed-source or proprietary models are controlled by companies that manage access, infrastructure, and updates through cloud platforms. These systems often benefit from large-scale infrastructure, safety controls, and ongoing optimization.
Open-weight models, meanwhile, release their trained parameters so developers and organizations can inspect, customize, and sometimes run models locally. This can offer advantages such as greater transparency, improved control over sensitive data, and reduced dependence on cloud providers.
The future will likely see both approaches persist: closed frontier models pushing capability boundaries and open-weight models bringing those capabilities to a far broader range of users, organizations, and use cases.
The future of AI-powered search
Search is one of the areas where LLMs are having the most visible and immediate impact on everyday users. The model is shifting from a list of links toward synthesized, conversational answers.
The next phase of this shift goes beyond AI-generated answers into agentic search systems that don't just retrieve and summarize information but will potentially be able to navigate the web, cross-reference sources, and complete multi-step research tasks on a user's behalf.
FAQ
What is the difference between AI and LLMs?
Are LLMs the same as ChatGPT?
Can large language models think like humans?
What industries use LLMs the most?
Are LLMs safe to use?
What is the best large language model today?